سرعت
سریعتر به نتیجه برسید: یک کلید، صدها مدل، و اتصال ساده به محصولتان.
دورهٔ آزمایشی خصوصی · دسترسی با حساب بیسیکس
تینکس
یک کلید، صدها مدل، هزینهٔ ماهانه به تومان — شفاف، با سقف روشن، بخشی از بیسیکس.
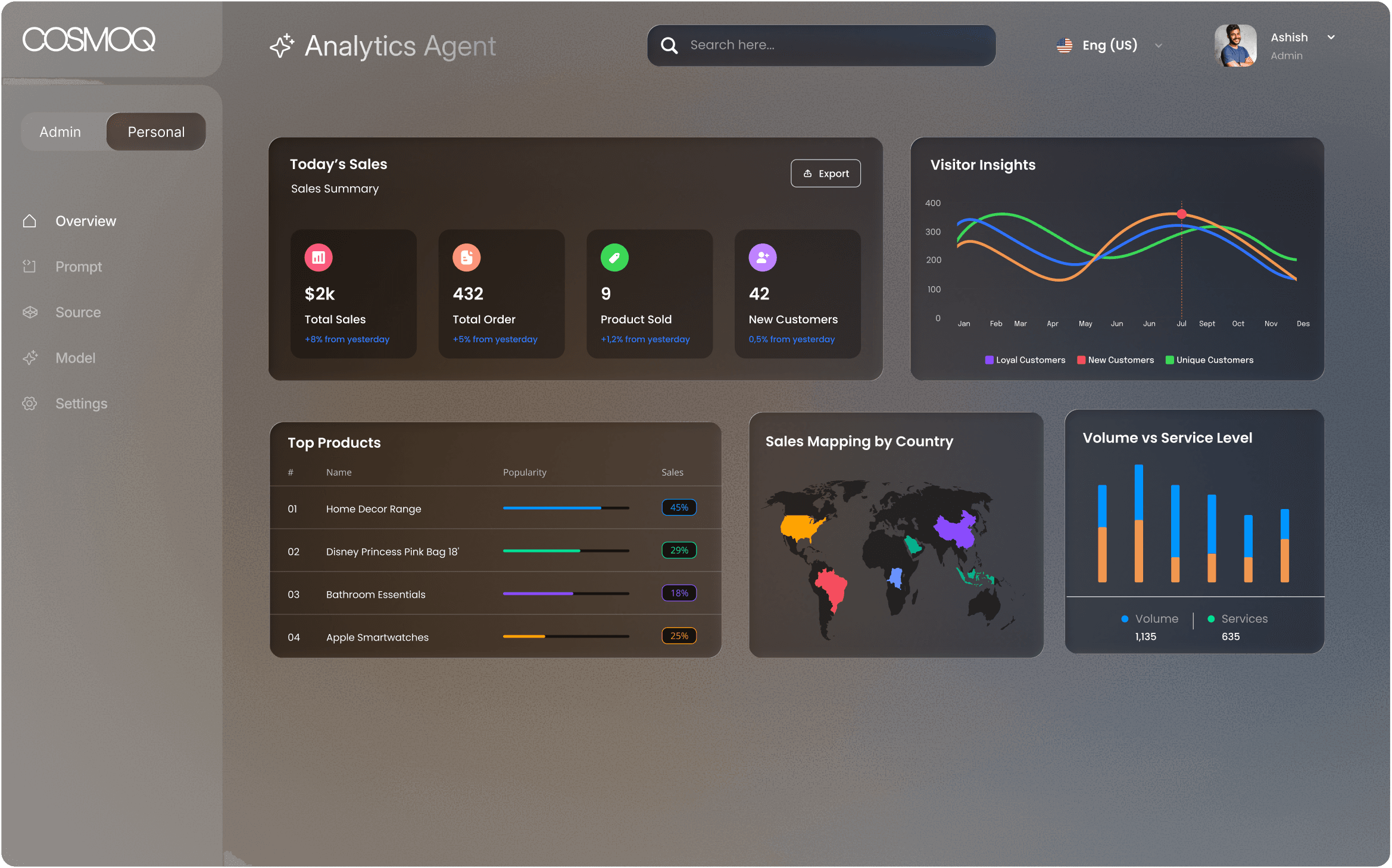
کارایی، اتوماسیون و نوآوری را در هر جریان کاری باز کنید — با هزینهٔ روشن و بدون پیچیدگی اضافه.
تمایزها
هوشمندتر، سریعتر و قابلکنترلتر از راهحلهای پراکنده.
سریعتر به نتیجه برسید: یک کلید، صدها مدل، و اتصال ساده به محصولتان.
از مدلهای سبک تا قوی — همه از یک درگاه، متناسب با کار واقعی تیم محصول.

بودجهٔ ماهانه به تومان مشخص است. وقتی اعتبار تمام شود، درخواستها قطع میشوند.

با همان حساب بیسیکس کار میکند و کنار بِریکس و پروداکتس مینشیند.
قابلیتها
ساده کنید، سرعت بگیرید، و با یک لایهٔ مشترک متحول شوید.
مصرف
به مدلهای روز دنیا از شرکتهای مختلف وصل شوید — بدون ساختن حساب جدا برای هر کدام. مدیریت مصرف در یک پنل.
فناوری
اگر قبلاً با ابزارهای رایج کار کردهاید، کافی است آدرس و کلید را عوض کنید. بقیه مثل قبل است؛ بدون بازنویسی کل پروژه.
داده و هزینه
هر پلن یک بودجهٔ اعتبار دارد. میبینید پولتان کجا میرود — نه عددهای تبلیغاتی گمراهکننده.
مراحل شروع
از ساخت حساب تا دیدن نتیجه — ساده و شفاف.
با همان حساب برای تینکس، بِریکس و پروداکتس وارد میشوید. پنل جدا لازم نیست.

از پنل کلید بسازید و مدل مناسب کارتان را انتخاب کنید — از سبک تا قدرتمند.
در محصولتان صدا بزنید و در داشبورد ببینید اعتبار چطور کم میشود.

داده و حریم خصوصی
از کلید امن تا قطع اعتبار وقتی بودجه تمام شود — لایهها کنار هم کار میکنند.

نظر کاربران
نتیجههایی که تیمهای محصول و فنی تجربه کردهاند.
«سقف ماهانهٔ تومانی یعنی تیم مالی از قبل میداند بودجه کجاست — نه سوپرایز آخر ماه.»
«یک کلید برای مدلهای مختلف، و قطع امن وقتی اعتبار تمام شود — مناسب API روی سرور.»
«همان حساب بیسیکس برای بِریکس، پروداکتس و تینکس؛ بدون فروشندهٔ جدا برای هر لایه.»
«سقف ماهانهٔ تومانی یعنی تیم مالی از قبل میداند بودجه کجاست — نه سوپرایز آخر ماه.»
«یک کلید برای مدلهای مختلف، و قطع امن وقتی اعتبار تمام شود — مناسب API روی سرور.»
«همان حساب بیسیکس برای بِریکس، پروداکتس و تینکس؛ بدون فروشندهٔ جدا برای هر لایه.»
«سقف ماهانهٔ تومانی یعنی تیم مالی از قبل میداند بودجه کجاست — نه سوپرایز آخر ماه.»
«یک کلید برای مدلهای مختلف، و قطع امن وقتی اعتبار تمام شود — مناسب API روی سرور.»
«همان حساب بیسیکس برای بِریکس، پروداکتس و تینکس؛ بدون فروشندهٔ جدا برای هر لایه.»
«سقف ماهانهٔ تومانی یعنی تیم مالی از قبل میداند بودجه کجاست — نه سوپرایز آخر ماه.»
«یک کلید برای مدلهای مختلف، و قطع امن وقتی اعتبار تمام شود — مناسب API روی سرور.»
«همان حساب بیسیکس برای بِریکس، پروداکتس و تینکس؛ بدون فروشندهٔ جدا برای هر لایه.»
سوالات متداول
پاسخ سوالهای رایج دربارهٔ درگاه هوش مصنوعی ما.
یکپارچهسازی
به ابزارها و جریان کاری تیمتان وصل شوید — با یک درگاه مشترک.
گام بعدی
همهچیز تیمتان لازم دارد، در یک فضای ساده. متمرکز بمانید، هماهنگ بمانید.